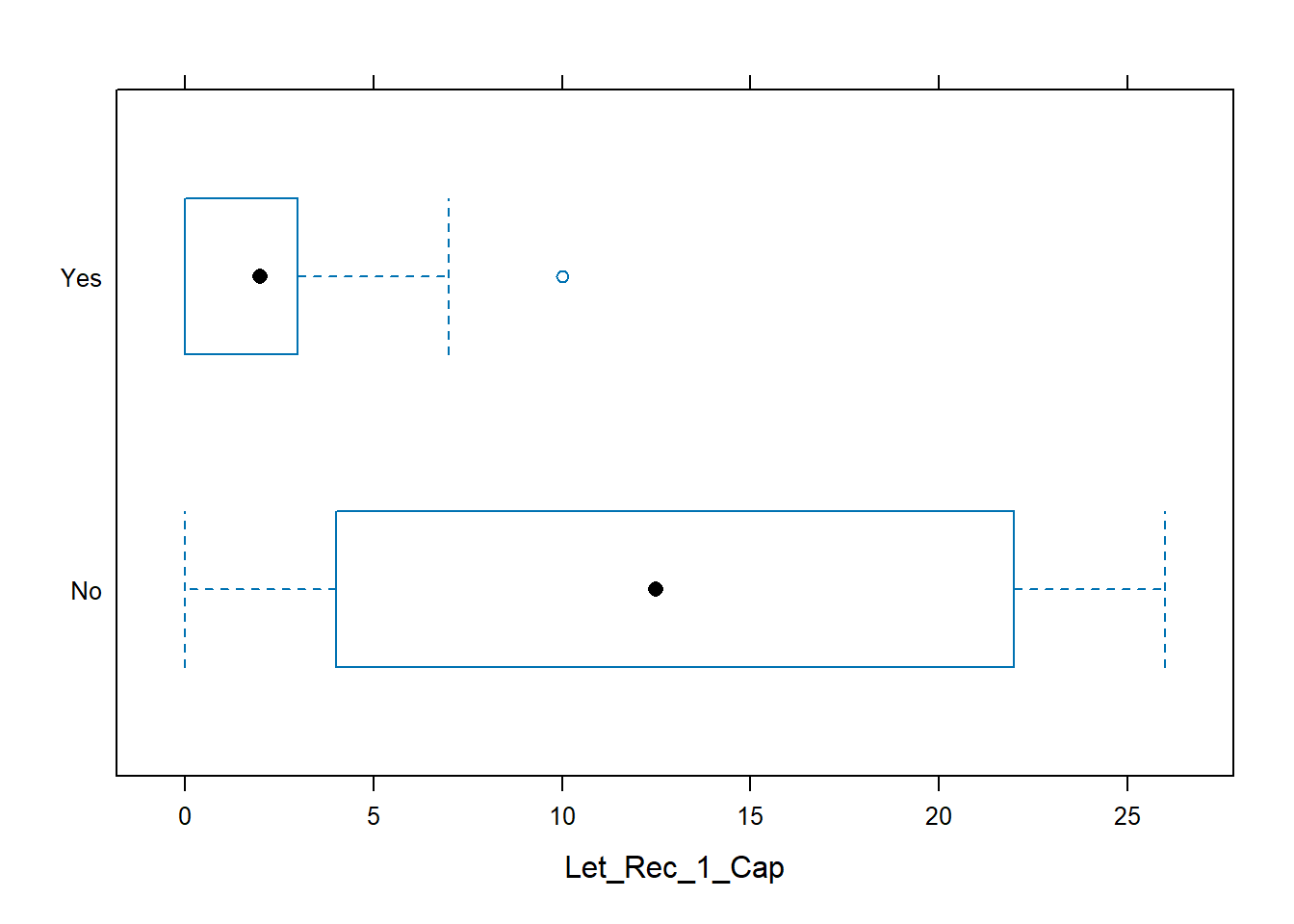
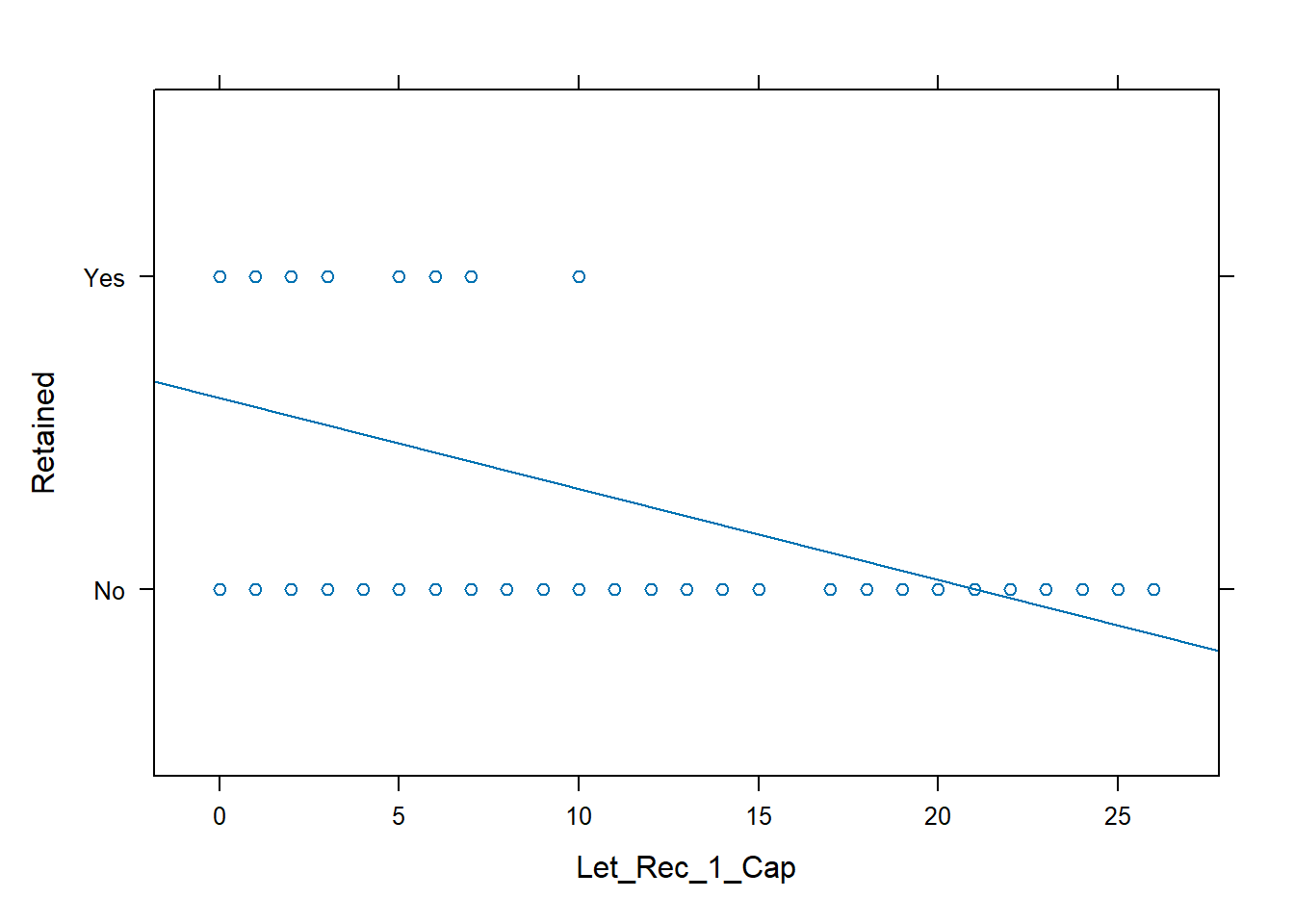
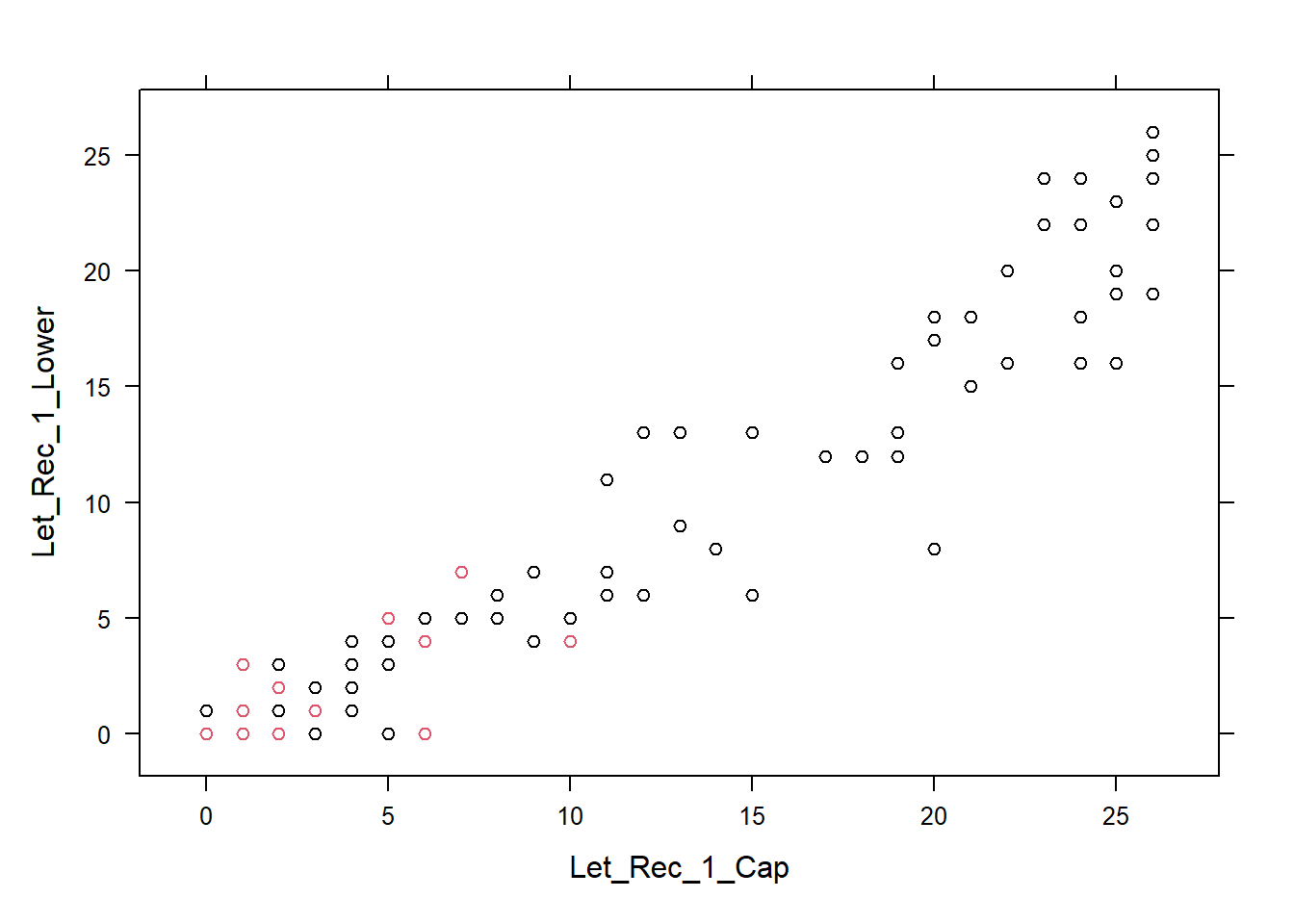
retention = read.csv("Data/logistic.csv")
head(retention) STUDID GENDER RACE BDAYMO BDAYYR BEHAVE1 BEHAVE2 ATTEND LETREC1C LETREC1L
1 28 0 2 6 89 1 1 0 23 22
2 139 0 2 5 89 2 2 10 26 24
3 164 1 1 5 89 2 2 0 5 0
4 201 1 2 9 89 1 2 3 21 18
5 221 0 3 12 88 1 1 13 6 4
6 318 1 3 10 89 4 3 17 7 5
NOREC1 NOREC2 TOTCHILD BRTHORDR BILING ROUND2 RETAINED TEACHER SCHOOL
1 10 12 3 2 0 1 0 2 1
2 20 20 2 1 0 1 0 4 1
3 3 4 2 1 0 1 1 4 1
4 19 20 5 4 0 1 0 2 1
5 2 7 4 3 0 1 1 1 1
6 8 11 3 3 0 1 0 2 1
LETREC2C LETREC2L AGE1290 RACE1 RACE2 RACE3 RACEO SCHOOL2 TEACHER1 TEACHER2
1 26 25 18 0 1 0 0 0 0 1
2 26 26 19 0 1 0 0 0 0 0
3 5 0 19 1 0 0 0 0 0 0
4 26 22 15 0 1 0 0 0 0 1
5 10 4 24 0 0 1 0 0 1 0
6 19 15 14 0 0 1 0 0 0 1
TEACHER3 TEACHER4 TOTORDR LR1CRND2 ORDRRND2 TOTCRND2 R2ORDR R2TOT
1 0 0 6 23 2 3 2 3
2 0 1 2 26 1 2 1 2
3 0 1 2 5 1 2 0 0
4 0 0 20 21 4 5 4 5
5 0 0 12 6 3 4 0 0
6 0 0 9 7 3 3 0 0 names(retention) [1] "STUDID" "GENDER" "RACE" "BDAYMO" "BDAYYR" "BEHAVE1"
[7] "BEHAVE2" "ATTEND" "LETREC1C" "LETREC1L" "NOREC1" "NOREC2"
[13] "TOTCHILD" "BRTHORDR" "BILING" "ROUND2" "RETAINED" "TEACHER"
[19] "SCHOOL" "LETREC2C" "LETREC2L" "AGE1290" "RACE1" "RACE2"
[25] "RACE3" "RACEO" "SCHOOL2" "TEACHER1" "TEACHER2" "TEACHER3"
[31] "TEACHER4" "TOTORDR" "LR1CRND2" "ORDRRND2" "TOTCRND2" "R2ORDR"
[37] "R2TOT"